To continuously improve how policies are developed, governments need to understand how policies actually affect people’s day-to-day lives. Doing this well requires data, and lots of it. But expanding the use of data in government also increases concern about individual privacy and the reach of the state.
We’ve found a way to ease the research process without sacrificing individual privacy. If widely adopted, we believe it will lead to better, faster, more policy-relevant research being produced by academics, research institutes and government departments themselves.
The solution we are proposing is synthetic data, but perhaps not as you currently know it. (And if you’re like most people, you don’t currently know it at all.)
The Behavioural Insights Team, funded by Administrative Data Research UK (ADR UK), investigated why synthetic data isn’t being adopted by the UK government, and whether we may be missing opportunities to accelerate public policy research.
Synthetic data is like an artist’s impression of the information
Synthetic data is like taking some original data and smudging it to look more like an artist’s impression. It’s a new version of a data set that is generated at random, but made to follow the structure and some of the patterns of the original data set. Each piece of information in the data set is meant to be plausible (e.g. an athlete’s height will usually be between 1.5 and 2.2 metres, and would never be 1 kilometre), but it is chosen randomly from the range of possible values, not by pointing to any original individual in the data set.
Some people claim it is the perfect solution to performing research on private data because it can be created at different levels of fidelity to more closely or loosely match the original data. With high-fidelity synthetic data, relationships in the data, such as correlations, are preserved. We can see overall what the data set looks like, and the variables within it, but if we zoom in too much we’re not getting a high resolution picture of an individual.
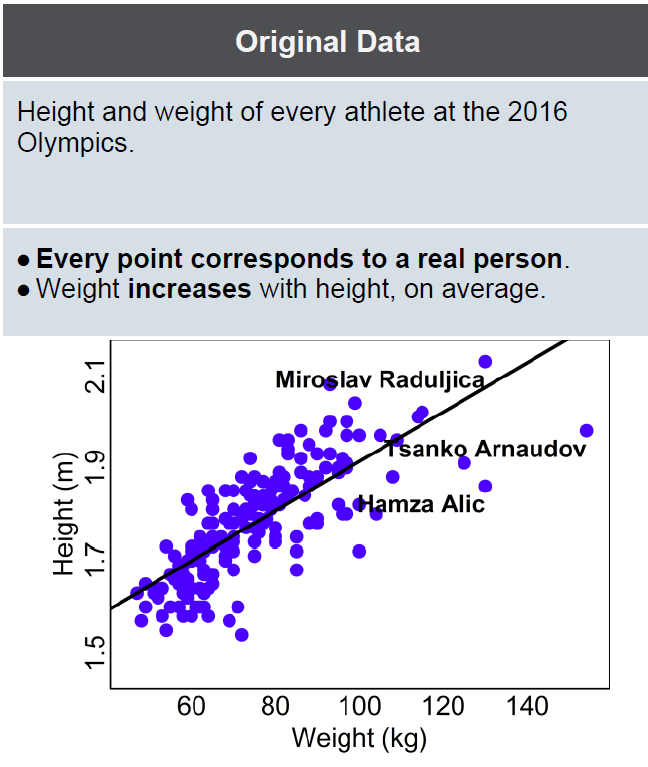
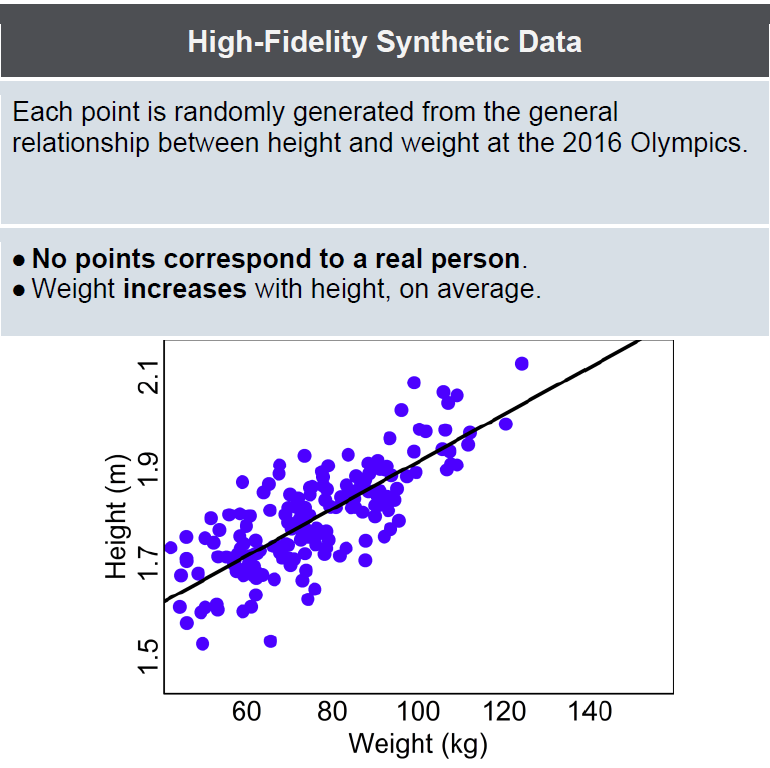
Using high-fidelity synthetic data you can run statistics and often get the right answer, but no actual individual’s information is present. In the athlete example, you could establish that weight and height are strongly correlated (taller people tend to be heavier) and to what extent (the correlation is about 60%) without being able to check Usain Bolt’s height or weight, or even knowing whether Usain Bolt was in the original data set at all.
However, it’s not all rosy. Critics are concerned that the privacy guarantees of high-fidelity synthetic data are not ironclad, and also that the randomness introduced to improve privacy could harm the accuracy of research (the U.S. Census Bureau’s move to synthetic data is worrying researchers). We tend to agree, and perhaps more importantly, so do the people that hold the data and decide whether to release it.
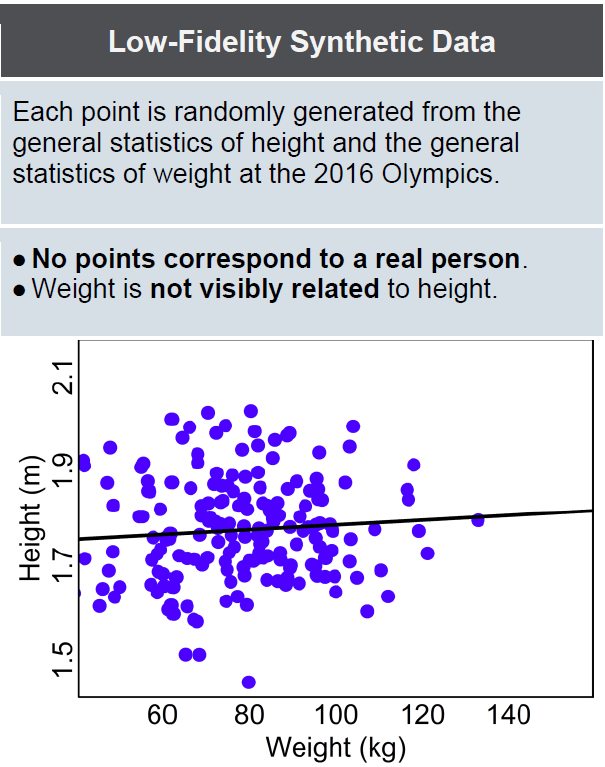
But there’s a different way to use synthetic data that is lower risk and more private, yet could accelerate policy research in all areas of government. Low-fidelity synthetic data doesn’t preserve any of the relationships between any of the columns of data, so in the athlete example, weight and height would not be related, but any row of data would still have a sensible weight or height, and they would be stored in the same format as the weight and height information in the original data. Low-fidelity data, because it is based on such a simplified view of the data set, has a much lower risk of exposing or disclosing any personal information.
Having a data set like this, without any real or accurate individual information, still allows a researcher to understand what a data set looks like. This helps them make a more informed decision about what they might be able to learn from the real data, if they were to get access to it, or if it isn’t worth pursuing an application. There are too many examples of researchers following time-consuming legal and ethical processes to obtain data, only to eventually find that it doesn’t contain the information they thought it would, or is too hard to use for their project. This is inefficient and frustrating, and a waste of resources. Providing low-fidelity synthetic data early in the process, without requiring full ethical and legal processes (because there is no personal data involved), would side-step much of this.
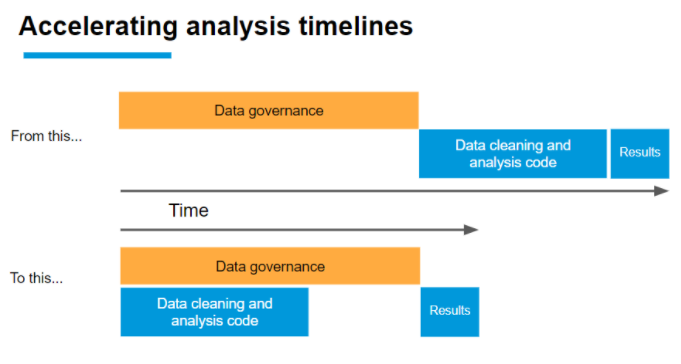
It can also help when there is a delay before a researcher will be able to receive the data (which is very common when individual privacy is involved because there are, appropriately, many ethical and legal processes to navigate). If low-fidelity synthetic data is available, the researcher can begin figuring out how precisely they will analyse it when it does arrive. In many cases they can write their entire analysis plan (and even their analysis code), figure out all the quirks, and get others to check it over, using only this low-fidelity synthetic data. When the real data arrives, they can be prepared to deliver results much faster, as illustrated below.
Low-fidelity synthetic data can also be used in researcher training. Many data sets are unique in the way they are laid out or the way they work. ADR UK is expanding its training programmes to help researchers understand how to work with important data sets that work or are linked together in surprising or unusual ways. Synthetic data can be used as the bedrock for training; researchers can work with a synthetic copy to really understand how each type of data set works and be trained appropriately, without requiring each trainee to write an application to use each data set.
Unfortunately synthetic data is currently poorly understood, especially the distinction between high-fidelity and low-fidelity, and the benefits of low-fidelity synthetic data. It is not yet a widely known technology in government, even among government analysts and researchers. We and others are trying to change that, because we think this is a substantial missed opportunity.
We’re making it easy
As well as getting the word out, we have also released a Python notebook that guides a user through generating low-fidelity synthetic data. This is designed to be self-explanatory for anyone who works with data – even if they have limited experience with Python. The main reason we wrote this new notebook is that existing tools, methods and tutorials for generating synthetic data focus on high-fidelity synthetic data. By writing a guided script that only generates low-fidelity, lower risk synthetic data, we keep things simpler and safer for researchers and data owners.
BIT and ADR UK are also talking to the Office for National Statistics (ONS) about how to integrate this approach with the ONS Secure Research Service and the forthcoming ONS Integrated Data Service. Creating a central platform where synthetic data sets are available to browse by researchers could open up new possibilities for policy-driven research and cross-government collaboration. We are missing out on scores of valuable research projects simply because researchers don’t know that the data they’d need is actually available somewhere across government.
For government policy and services to work well for society and citizens, they must be built on good data. The widespread use of low-fidelity synthetic data can support that aim by making research safer, easier and quicker. Try out our code, make your data more widely available (or ask your partners if they could), and if you want to learn more, read the full report.