
“Village doctors” are the primary healthcare providers for many Bangladeshis, but their qualifications and expertise can vary considerably. In the wake of the coronavirus pandemic, the role of village doctors has expanded to pandemic preventers and the advice they provide has become a matter of public health. With that in mind, we partnered with BRAC, the largest NGO in the world, and health-tech start-up Jeeon, to evaluate their flagship ‘village doctor’ training programme in Bangladesh.
The programme endeavours to provide village doctors the skills they need to manage the pandemic. In practice this means training them how to provide the correct medical care for coronavirus patients and ensuring the advice they give is in line with the latest COVID-19 evidence. BIT evaluated two versions of this training programme; an “offline” in-person training session and an online training session accessed through mobile phones, to measure the impact of each on village doctor knowledge. See the offline training below:

Both the online and offline training increased village doctor knowledge equally. Our follow up evaluation was unable to detect a difference in patient outcomes. You can see the knowledge scores collected after training charted below:
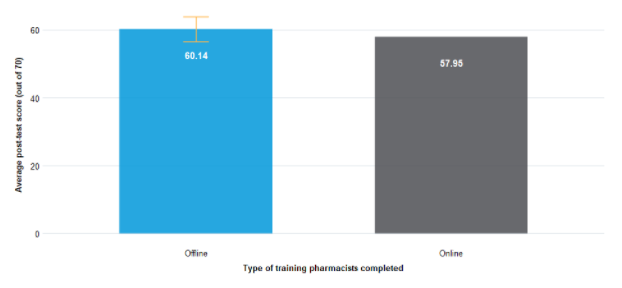
Let’s restate the result above in a different way: we tested training interventions, and we got a null result – isn’t that bad?
Null results, where there is no detectable difference between trial conditions, is something that most of us who deal in policy experiments are familiar with. It is certainly tempting to think of them as a disappointment – our interventions “didn’t work” – and that is probably the most common lay interpretation.
However it is not the only interpretation. Actually, a “null” can have several possible explanations. Here are a couple of examples that we’ve sampled from this excellent summary:
- Intervention design null — this is the first place your mind may go when you read the word “null”. It signifies that the reason you are not seeing an effect is because of an issue with the intervention. This could be that you have misunderstood the context in which you are trying to change behaviour, but it could also be that you just didn’t have a high enough intervention “dose”.
- Study design null – this is where the cause of the null isn’t the intervention, but the evaluation. You might be underpowered to detect a small effect; or perhaps you are measuring the wrong item or the wrong people.
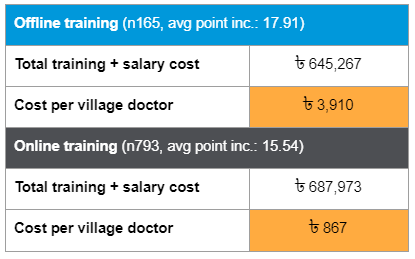
However, for evaluating online versus offline training, our null result really is good news. That’s because the fact that there is no difference in knowledge outcomes between the two forms of training suggests that the much cheaper online option is just as good as the expensive in-person training programme. We know this because we worked with Jeeon’s project management and finance teams to construct a cost effectiveness analysis – you can see below that online training costs only ৳ 867 (around £7.40) per village doctor:
Fundamentally, how we interpret our results is as important and nuanced as any other part of the research process. Whether you are cheering in your seat at a whopping effect size or staring hopelessly at a null, it is important to work through all the possible explanations. This is because interpretation of results is a moment where it is very easy for biases to creep in. Take, for example, this adversarial study to test whether eye movement affected memory recall, where two teams of “skeptic” and “proponent” authors collected and analysed the same data on the same protocol and nevertheless produced opposite interpretations.
What do we do to avoid misinterpreting results, positive, negative or neutral? There are a few useful strategies we use at BIT. These include:
- Calculate experimental power. Knowing what you are powered to detect can help immensely in planning your study as well as interpreting results correctly. It is also increasingly easy using online tools or statistical programming (and even Excel).
- Get forecasts on results, in advance. Getting peers and fellows to forecast the expected result can also be helpful: if you’re powered to detect an effect of the forecasted size, and you then find a null, that null suddenly becomes very informative!
- Prespecify possible interpretations with specific policy actions. Thinking through what different results would mean in practice can help you add in the necessary measures to confirm this, and guard against later misinterpretation driven by confirmation bias.
In our case, our protocol for evaluation confirmed that in the event of a null we would treat both trainings as being effective and seek alternate measures to inform our recommendation to BRAC and Jeeon. In practice, we spoke to Jeeon about their experiences of both, feedback they’d received, and ended up working with them to carry out the cost-benefit analysis. This led us to the happy conclusion that Jeeon’s training of village doctors helped improve knowledge, and that the online training is an impactful and cost-effective way to do so.
With thanks to both Jeeon and BRAC, both fantastic organisations that are doing incredibly important work in Bangladesh around COVID-19 response and more. If you want to find out more about BIT’s work in Bangladesh – including the cluster RCT on handwashing we are analysing, results due in August – please get in touch!





