Dozens of studies have shown that the choices we make over what we eat, how we save, and even how we vote can be affected by how those choices are presented: their ‘choice architecture’.
Research has found, for example, that the order of candidates’ names on a ballot sheet can influence election outcomes (you want to be first). Others have found that our perceptions of colours and our measures of quality are often relative and can be influenced by what we’ve experienced immediately before. For example, studies into what’s called ‘successive contrasting’ have found that certain species of animal – like honeybees – will abandon otherwise healthy feeding grounds if they’ve just been in plentiful settings: ‘good’ can seem ‘bad’ when in contrast to ‘excellent’. Studies on humans have shown that how attractive someone seems is at least in part a function of how attractive the last person you saw was! In all, the judgements we make can be highly contextual.
At Applied – the Behavioural Insights Team’s first spin-out venture – we’re all about making sure that the best person gets the job. And that means we want to remove as much of the luck, noise, and bias in candidate review as we can. So we set out to test whether any of these quirky ordering effects played out with hiring decisions, and if so, what we could do to eliminate them.
What we wanted to know
-
- Do reviews become more ‘accurate’ over time?
- Is there an advantage (to candidates) of being first?
- Are scores given to candidates affected by who came before them?
How we designed the experiment
Last year, we invited about 150 reviewers on an online research platform to rate the responses by 80 candidates to four work-related challenges. Each reviewed 100 unique responses, drawn from real candidates that had previously applied to a position at the Behavioural Insights Team.
In keeping with our unbiased review methodology, the responses of all candidates were anonymised, chunked by question, and the order of their responses within each question was randomised across every reviewer. That is, each reviewer scored a batch of randomly ordered responses to question 1 and then a batch of randomly ordered responses to question 2, and so on. Armed with a guide, they rated each response on a scale of 1 (unsatisfactory) to 5 (exceptional) stars without seeing each other’s opinions. We then compared these to a benchmark score combining everyone’s opinion of that response.
The results
Finding 1: Do reviews become more ‘accurate’ over time?
Yep. Since we’d randomised across lots of reviewers, we could compare whether the score given to a particular response was different if the reviewer read it as the first in the batch, or 9th, 17th, or last. For each reviewer, we calculated the difference of their rating from the average score (of all 50 reviews). If for example, I scored a particular response a 4, but the average of all the reviewers’ scores was 3, then we would calculate my deviation on that response to be 1.
Figure 1: Average deviation from objective mean by response order

Figure 1 shows that the average deviation from the benchmarked rating is higher for responses that are rated at the very beginning of the review process. Average deviation falls by roughly 17 per cent from the first to the last rated response for question one, and this result was highly statistically significant.
Finding 2: Is there an advantage to being first?
Yep. The average rating across all candidates is 3.35, but being rated first increases that to 3.52. While those effects don’t sound big, that’s the same gap as between being ranked 1st (star) or 12th (borderline for interview), or 12th and 29th (rejected for interview) (see Figure 2 below).
Figure 2: Average scores by rank order (black bars represent the gap in rank equivalent to being seen first)
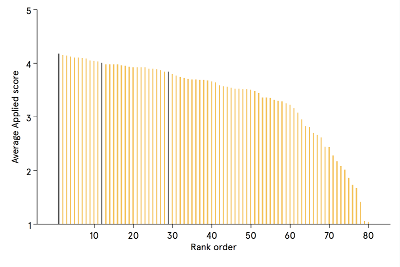
Interestingly, the positive effect of being first appeared for the first question, but also for each subsequent question. Combined with finding 1, this suggests that reviewers go through some general calibration when they start off, but also that they also calibrate slightly within each question.
Finding 3: Does it matter who comes before you?
Yep. We took the top ten and bottom ten candidates on each question (as rated by all reviewers) and looked at what impact seeing that response had on the scores for the next few candidates.
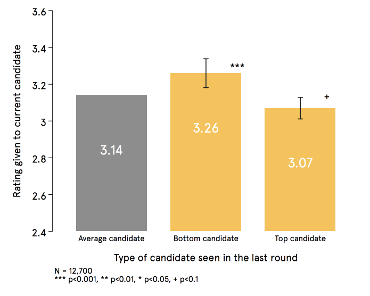
We found quite strong evidence that scores given to candidates were affected by the strength or weakness of the candidate seen immediately before, even controlling for our earlier findings. An average candidate appears worse (and gets a lower score) if they come after a phenomenal candidate, but they’ll seem far better (and get a higher score) if they come after a poor one (see Figure 3). These ‘spillover’ effects are more extreme in the latter case, and it turns out that they affect more than just the next candidate: two and three down the line benefit from having a poor candidate reviewed recently!
Figure 3: Scores for candidates rated immediately after a poor (bottom ten) and exceptional (top ten) performer (compared to candidates that do not fall in either category).
What to do?
Our experiment showed that as a candidate, you want to be seen first, or after a poor candidate. Trouble is, in life, you can’t affect how and when you’re reviewed.
Luckily, the solution is relatively simple: randomise.
We ran this experiment to find out if the way we had designed the Applied platform was optimal and we learned that it was. Applied’s review algorithm makes sure that candidate responses are randomised within each question and across all reviewers. So no response is read in the same order. This quite simple design choice turns out to make a world of difference.

